使用案例
使用案例
1、提示词 & 引用提示词
FastGPT 提示词 & 引用提示词说明
限定词从 V4.4.3 版本后去除,被“引用提示词”和“引用模板”替代。
1.1 AI 对话消息组成
传递给 AI 模型的消息是一个数组,FastGPT 中这个数组的组成形式为:
1 | [ |
Tips: 可以通过点击上下文按键查看完整的
1.2 引用模板和提示词设计
知识库采用 QA 对的格式存储,在转义成字符串时候会根据引用模板来进行格式化。知识库包含 3 个变量: q,a 和 source,可以通过 _posts/fastgpt/使用案例.md 按需引入。下面一个模板例子:
引用模板
1 | {instruction:"{{q}}",output:"{{a}}",source:"{{source}}"} |
搜索到的知识库,会自动将 q,a,source 替换成对应的内容。每条搜索到的内容,会通过 \n 隔开。例如:
1 | {instruction:"电影《铃芽之旅》的导演是谁?",output:"电影《铃芽之旅》的导演是新海诚。",source:"手动输入"} |
1.3 引用提示词
引用模板需要和引用提示词一起使用,提示词中可以写引用模板的格式说明以及对话的要求等。可以使用 来使用 引用模板,使用 来引入问题。例如:
1 | 你的背景知识: |
2、提示词案例
2.1 仅回复知识库里的内容
引用提示词里添加:
1 | 你的背景知识: |
2.2 说明引用来源
引用模板:
1 | {instruction:"{{q}}",output:"{{a}}",source:"{{source}}"} |
引用提示词:
1 | 你的背景知识: |
3、对接第三方 GPT 应用
通过与 OpenAI 兼容的 API 对接第三方应用
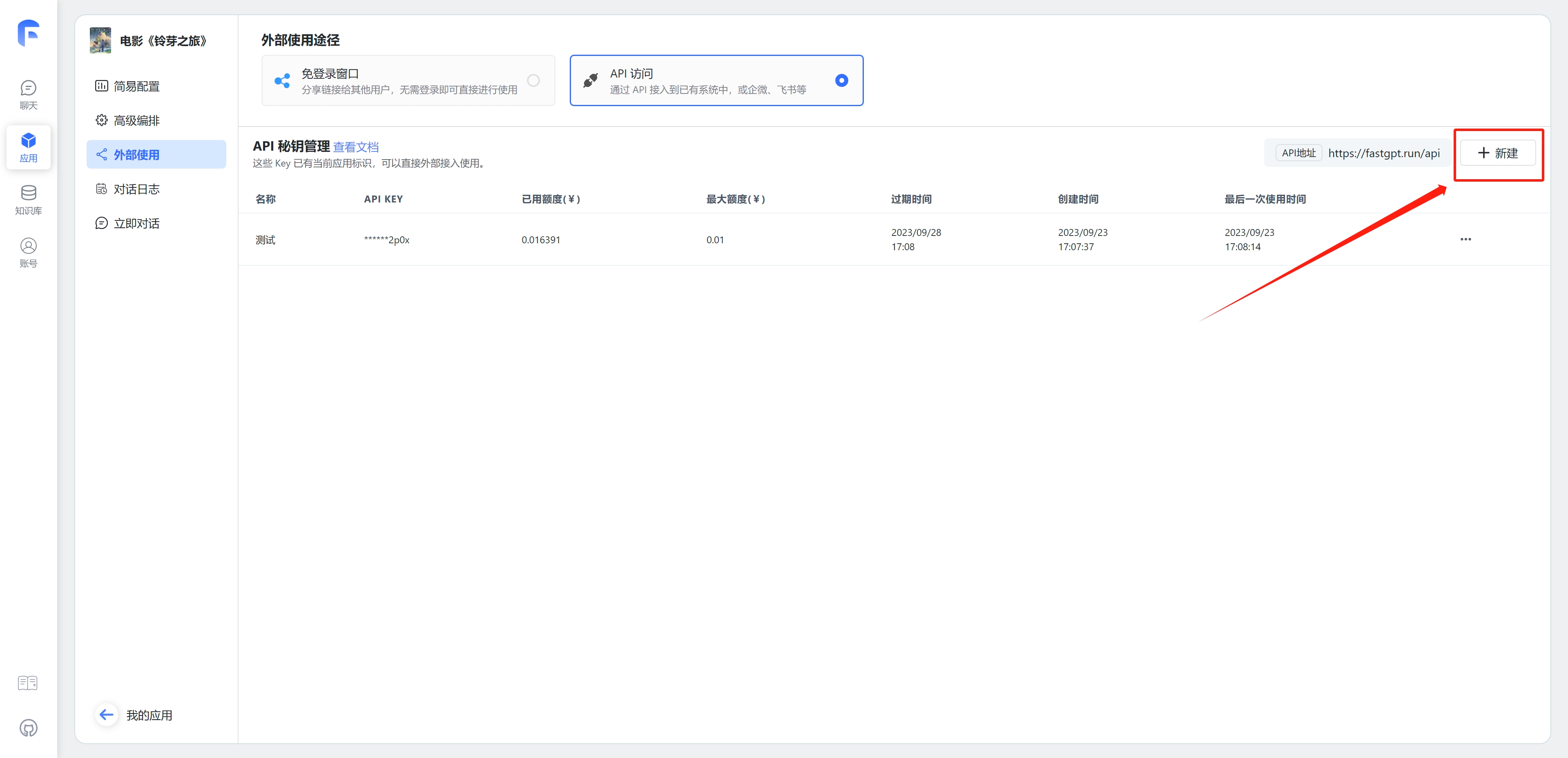
3.1 获取 API 秘钥
依次选择应用 -> 「API访问」,然后点击「API 密钥」来创建密钥。
warning
密钥需要自己保管好,一旦关闭就无法再复制密钥,只能创建新密钥再复制。
🍅
Tips: 安全起见,你可以设置一个额度或者过期时间,放置 key 被滥用。
3.2 替换三方应用的变量
1 | OPENAI_API_BASE_URL: https://fastgpt.run/api/openapi (改成自己部署的域名) |
ChatGPT Next Web 示例:
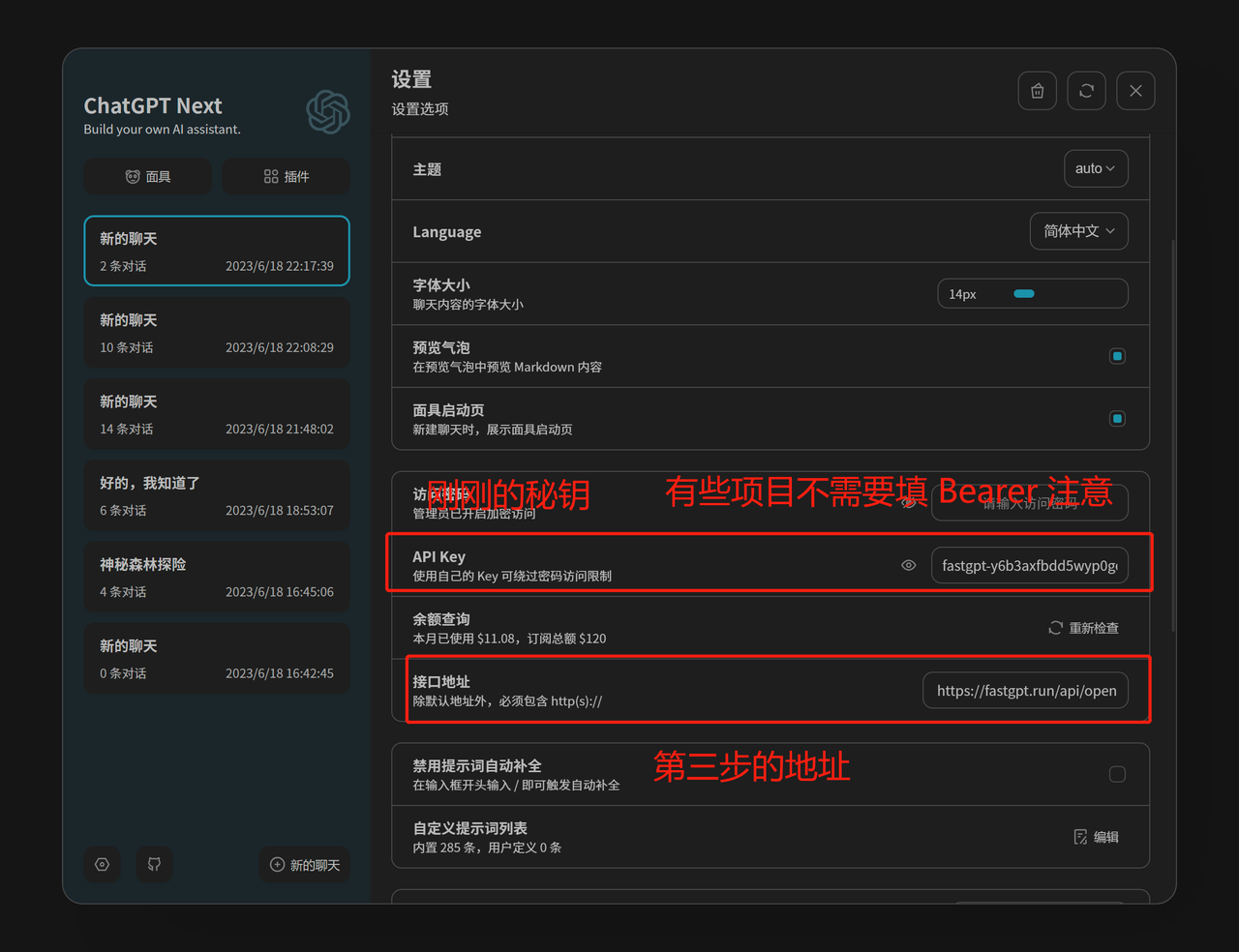
ChatGPT Web 示例:
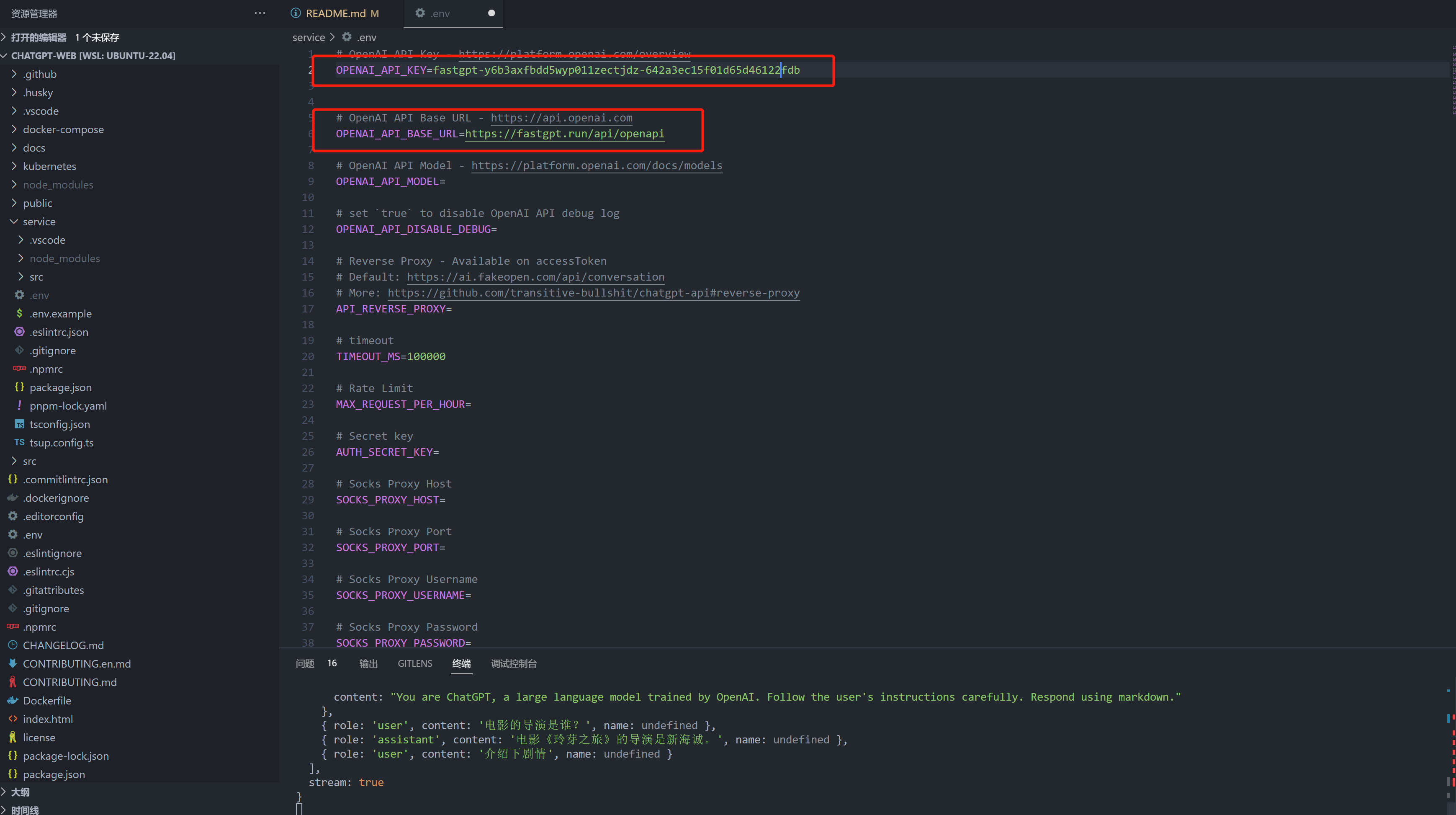
3.3 对接 chatgpt-on-wechat
FastGPT 对接 chatgpt-on-wechat
3.4 1 分钟对接 chatgpt-on-wechat
由于 FastGPT 的 API 接口和 OpenAI 的规范一致,可以无需变更原来的应用即可使用 FastGPT 上编排好的应用。API 使用可参考 这篇文章。编排示例,可参考 高级编排介绍
1. 获取 OpenAPI 秘钥
依次选择应用 -> 「API访问」,然后点击「API 密钥」来创建密钥。
密钥需要自己保管好,一旦关闭就无法再复制密钥,只能创建新密钥再复制。
3. 创建 docker-compose.yml 文件
只需要修改 OPEN_AI_API_KEY 和 OPEN_AI_API_BASE 两个环境变量即可。其中 OPEN_AI_API_KEY 为第一步获取的秘钥,OPEN_AI_API_BASE 为 FastGPT 的 OpenAPI 地址,例如:https://fastgpt.run/api/openapi/v1。
随便找一个目录,创建一个 docker-compose.yml 文件,将下面的代码复制进去。
1 | version: '2.0' |
4. 运行 chatgpt-on-wechat
1 | docker-compose pull |
- 运行成功后会提示扫码登录
- 随便找个账号,私信发送: bot问题 会将 问题 传到 FastGPT 进行回答。
3.5 接入飞书
FastGPT 接入飞书机器人
4、FastGPT 一分钟接入飞书
由于 FastGPT 的 API 接口和 OpenAI 的规范一致,可以无需变更第三方应用即可使用 FastGPT 上编排好的应用。API 使用可参考 这篇文章。编排示例,可参考 高级编排介绍
1. 获取 FastGPT 的 OpenAPI 秘钥
依次选择应用 -> 「API 访问」,然后点击「API 密钥」来创建密钥。 参考这篇文章
2. 部署飞书服务
推荐使用 Railway 一键部署
参考环境变量配置:
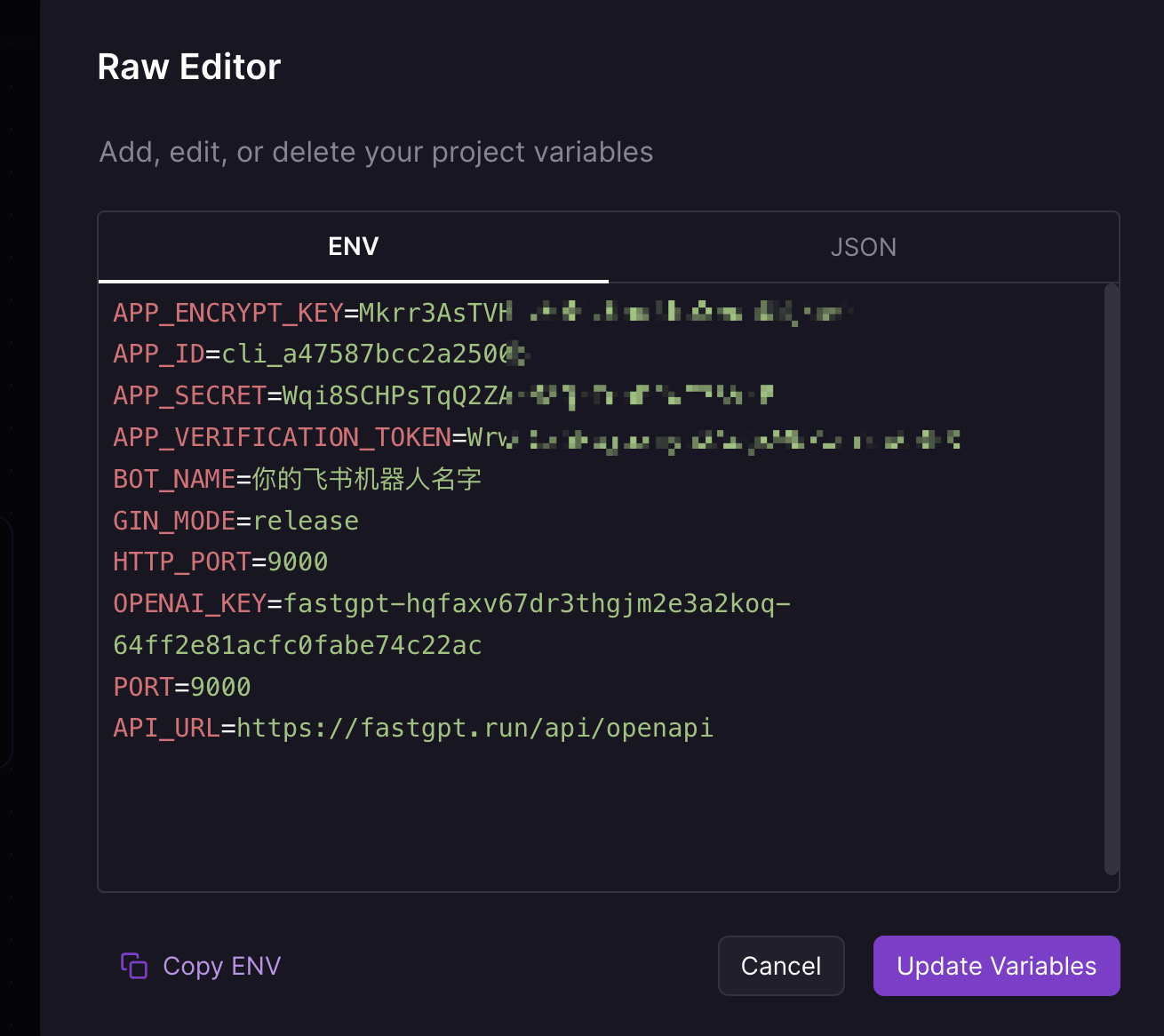
FastGPT 集成重点参数:
1 | #上一步FastGPT的OpenAPI 秘钥 |
3. 创建飞书机器人
前往 开发者平台 创建应用 , 并获取到 APPID 和 Secret
前往
应用功能-机器人, 创建机器人从 cpolar、serverless 或 Railway 获得公网地址,在飞书机器人后台的
1
事件订阅
板块填写。例如,
http://xxxx.r6.cpolar.top为 cpolar 暴露的公网地址/webhook/event为统一的应用路由- 最终的回调地址为
http://xxxx.r6.cpolar.top/webhook/event
在飞书机器人后台的
1
机器人
板块,填写消息卡片请求网址。例如,
http://xxxx.r6.cpolar.top为 cpolar 暴露的公网地址/webhook/card为统一的应用路由- 最终的消息卡片请求网址为
http://xxxx.r6.cpolar.top/webhook/card
在事件订阅板块,搜索三个词
1
机器人进群
、
1
接收消息
、
1
消息已读
, 把他们后面所有的权限全部勾选。 进入权限管理界面,搜索
1
图片
, 勾选
1
获取与上传图片或文件资源
。 最终会添加下列回调事件
- im:resource(获取与上传图片或文件资源)
- im:message
- im:message.group_at_msg(获取群组中所有消息)
- im:message.group_at_msg:readonly(接收群聊中 @ 机器人消息事件)
- im:message.p2p_msg(获取用户发给机器人的单聊消息)
- im:message.p2p_msg:readonly(读取用户发给机器人的单聊消息)
- im:message:send_as_bot(获取用户在群组中 @ 机器人的消息)
- im:chat:readonly(获取群组信息)
- im:chat(获取与更新群组信息)
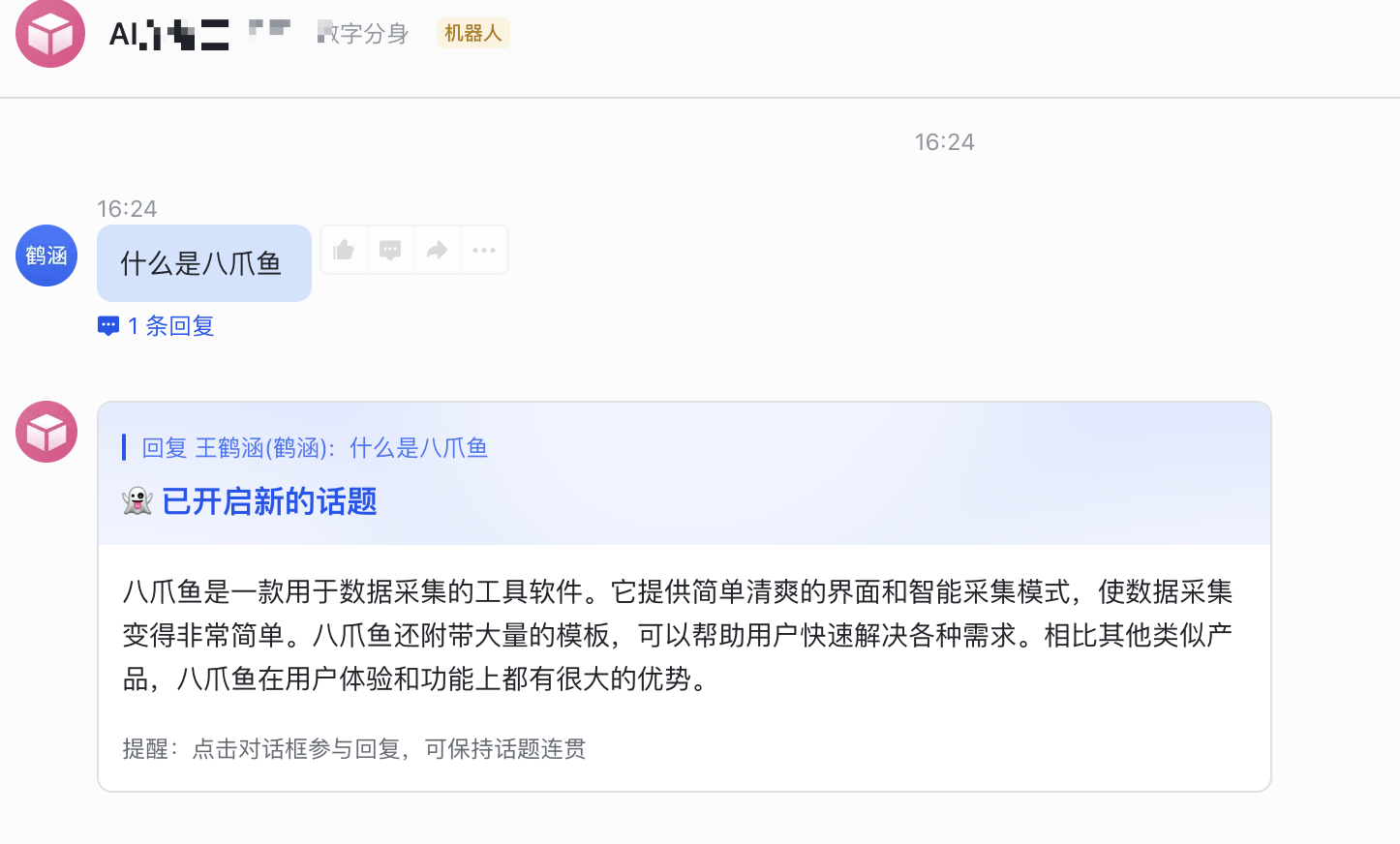
4. 测试飞书机器人
私聊机器人,或者群里艾特它,就可以基于 FastGPT 的应用进行回答啦
5、打造高质量 AI 知识库
利用 FastGPT 打造高质量 AI 知识库
前言
自从去年 12 月 ChatGPT 发布后,带动了新的一轮应用交互革命。尤其是 GPT-3.5 接口全面放开后,LLM 应用雨后春笋般快速涌现,但因为 GPT 的可控性、随机性和合规性等问题,很多应用场景都没法落地。
3 月时候,在 Twitter 上刷到一个老哥使用 GPT 训练自己的博客记录,并且成本非常低(比起 FT)。他给出了一个完整的流程图:
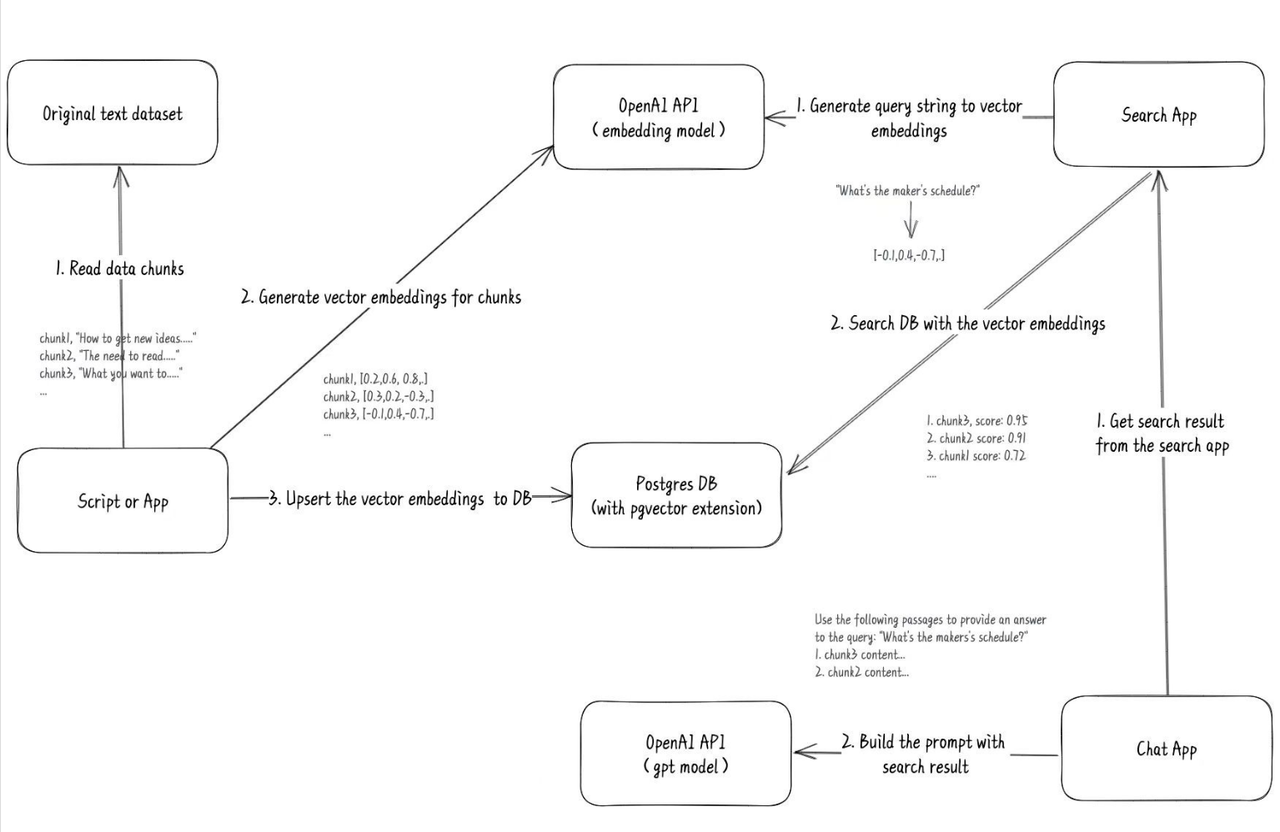
看到这个推文后,我灵机一动,应用场景就十分清晰了。直接上手开干,在经过不到 1 个月时间,FastGPT 在原来多助手管理基础上,加入了向量搜索。于是便有了最早的一期视频:
3 个月过去了,FastGPT 延续着早期的思路去完善和扩展,目前在向量搜索 + LLM 线性问答方面的功能基本上完成了。不过我们始终没有出一期关于如何构建知识库的教程,趁着 V4 在开发中,我们计划介绍一期《如何在 FastGPT 上构建高质量知识库》,以便大家更好的使用。
5.1 FastGPT 知识库完整逻辑
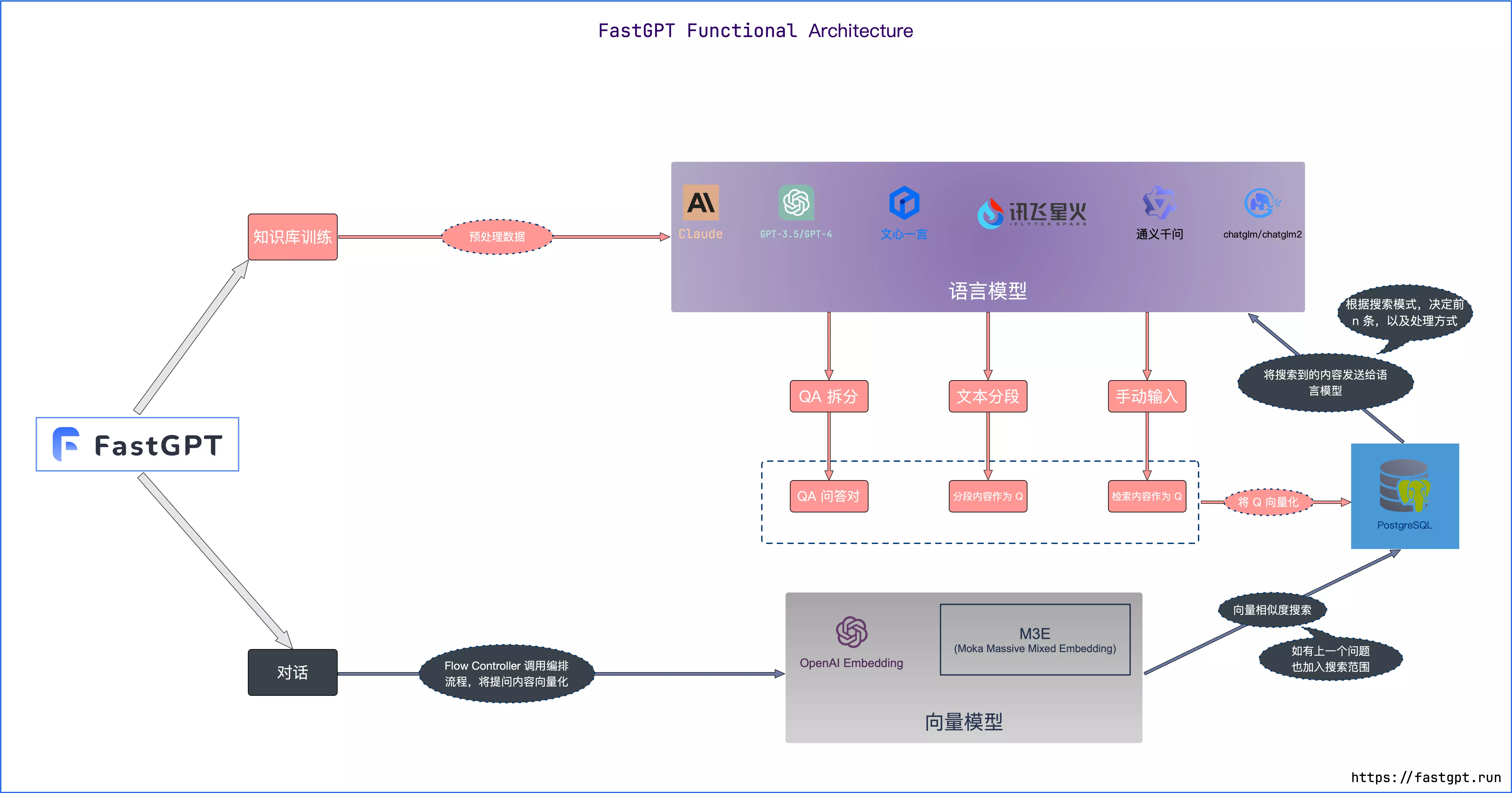
在正式构建知识库前,我们先来了解下 FastGPT 是如何进行知识库检索的。首先了解几个基本概念:
- 向量:将人类直观的语言(文字、图片、视频等)转成计算机可识别的语言(数组)。
- 向量相似度:两个向量之间可以进行计算,得到一个相似度,即代表:两个语言相似的程度。
- 语言大模型的一些特点:上下文理解、总结和推理。
结合上述 3 个概念,便有了 “向量搜索 + 大模型 = 知识库问答” 的公式。下图是 FastGPT V3 中知识库问答功能的完整逻辑:
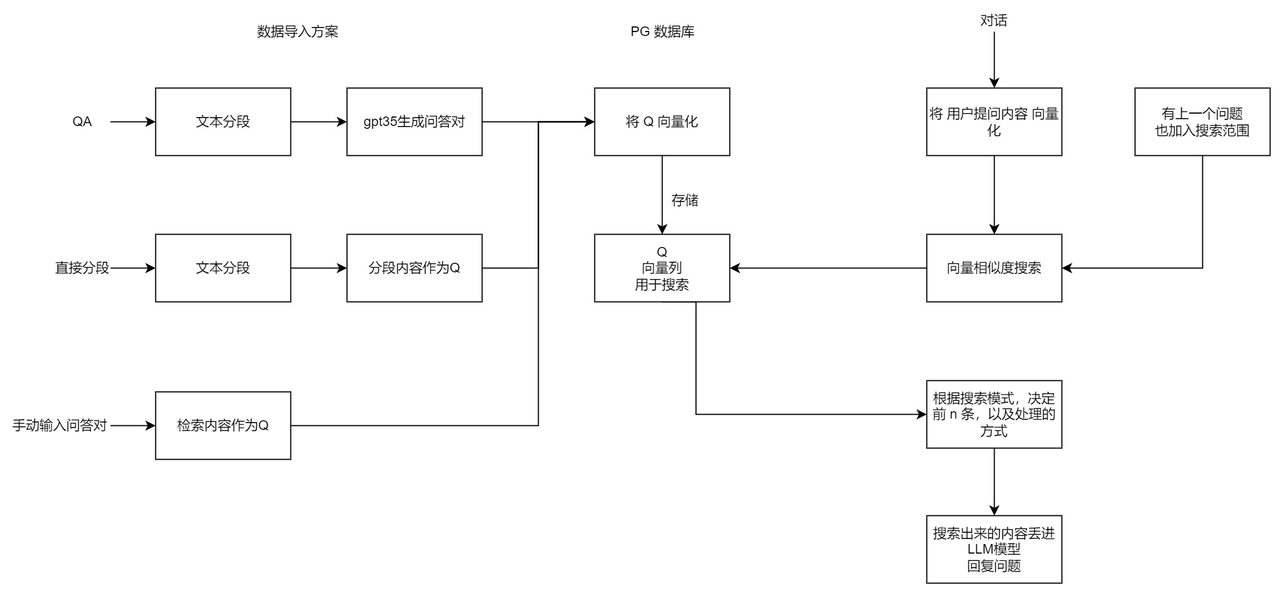
与大部分其他知识库问答产品不一样的是, FastGPT 采用了 QA 问答对进行存储,而不是仅进行 chunk(文本分块)处理。目的是为了减少向量化内容的长度,让向量能更好的表达文本的含义,从而提高搜索精准度。 此外 FastGPT 还提供了搜索测试和对话测试两种途径对数据进行调整,从而方便用户调整自己的数据。根据上述流程和方式,我们以构建一个 FastGPT 常见问题机器人为例,展示如何构建一个高质量的 AI 知识库。
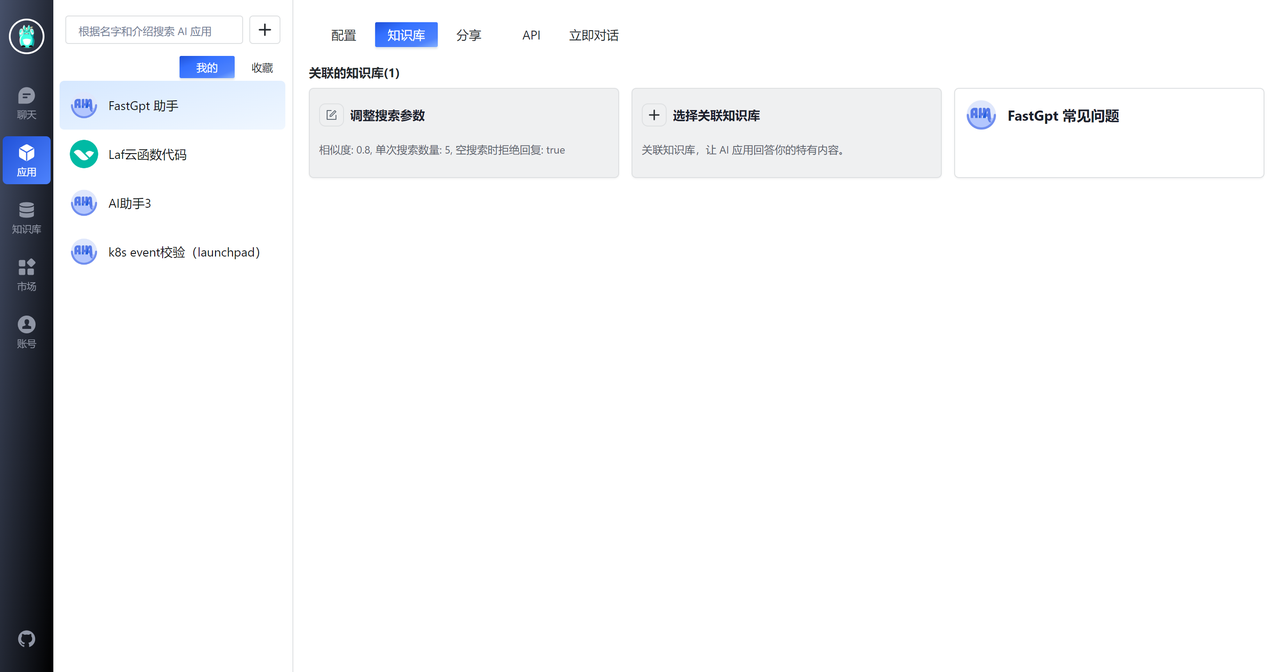
5.2 构建知识库应用
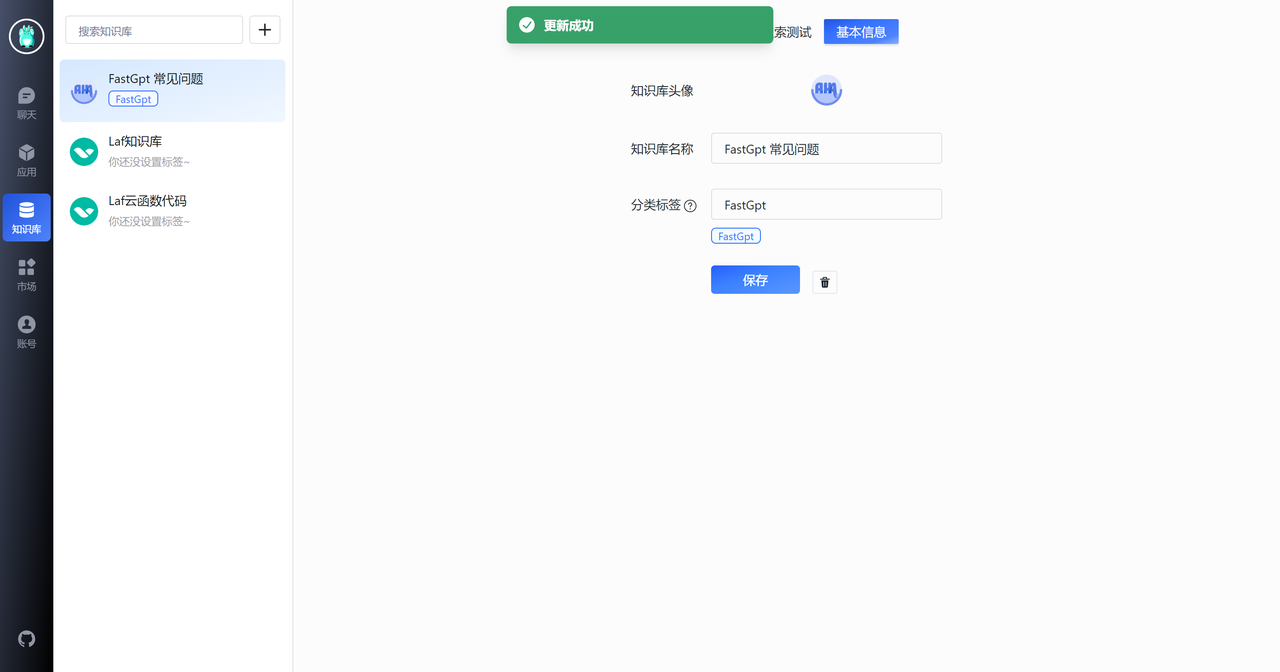
首先,先创建一个 FastGPT 常见问题知识库
5.3 通过 QA 拆分,获取基础知识
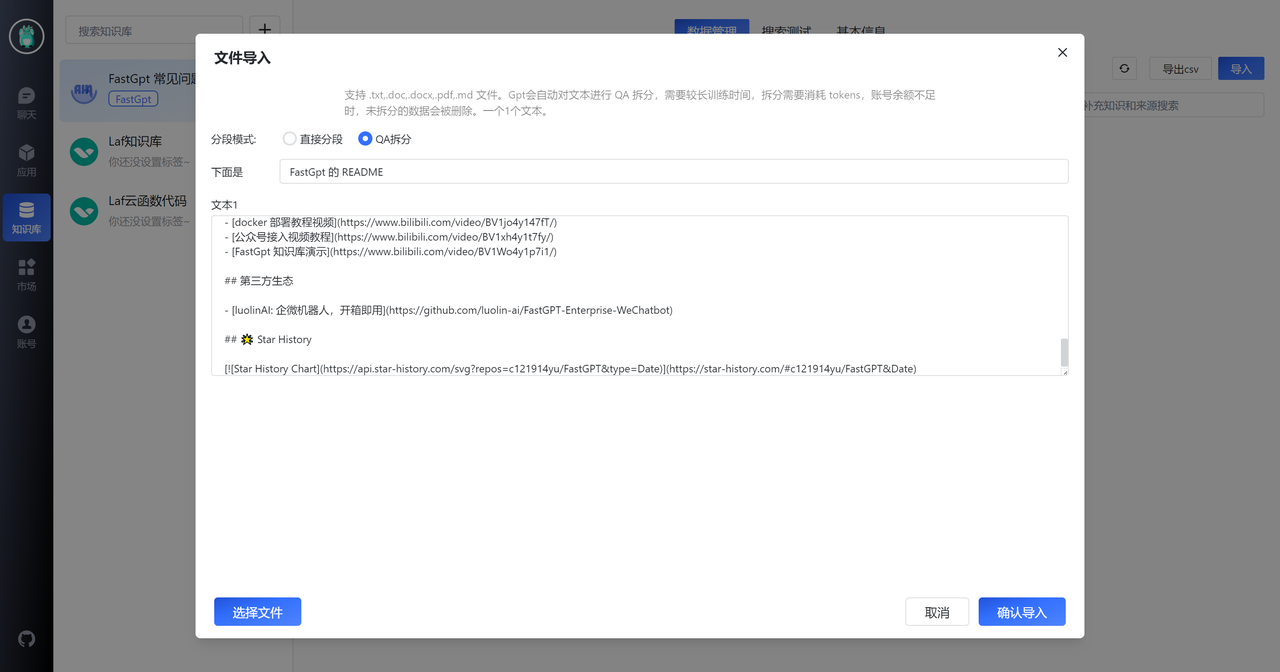
我们先直接把 FastGPT Git 上一些已有文档,进行 QA 拆分,从而获取一些 FastGPT 基础的知识。下面是 README 例子。
5.4 修正 QA
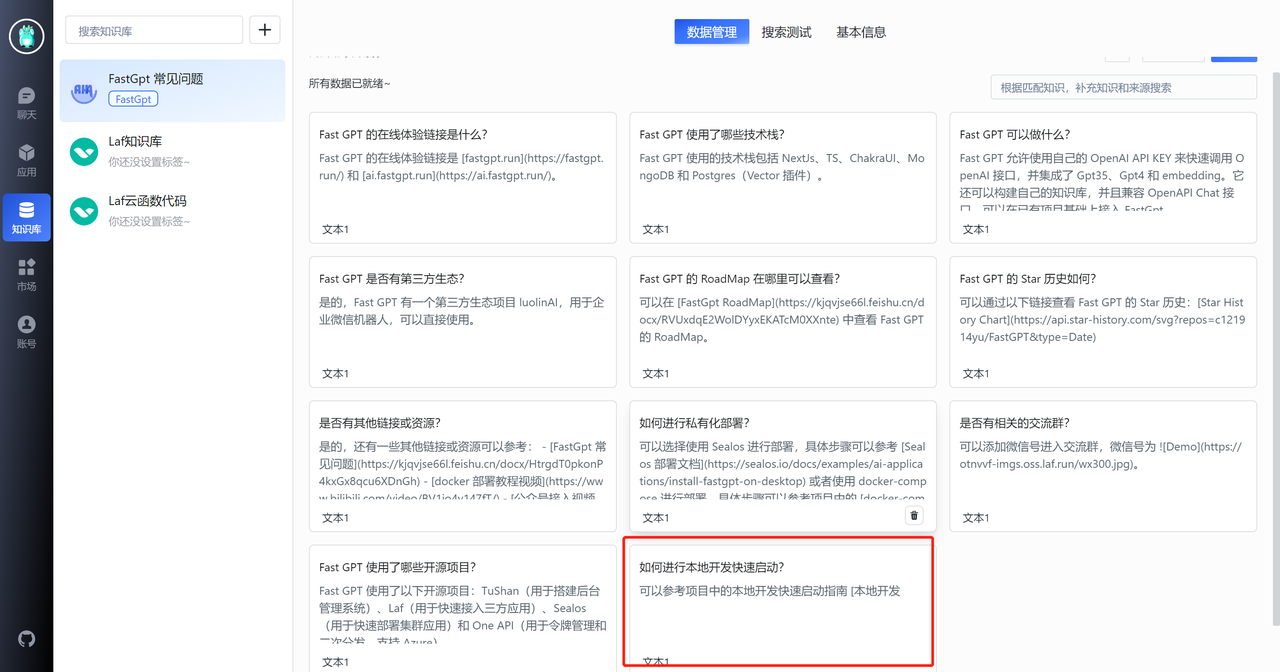
通过 README 我们一共得到了 11 组数据,整体的质量还是不错的,图片和链接都提取出来了。不过最后一个知识点出现了一些截断,我们需要手动的修正一下。
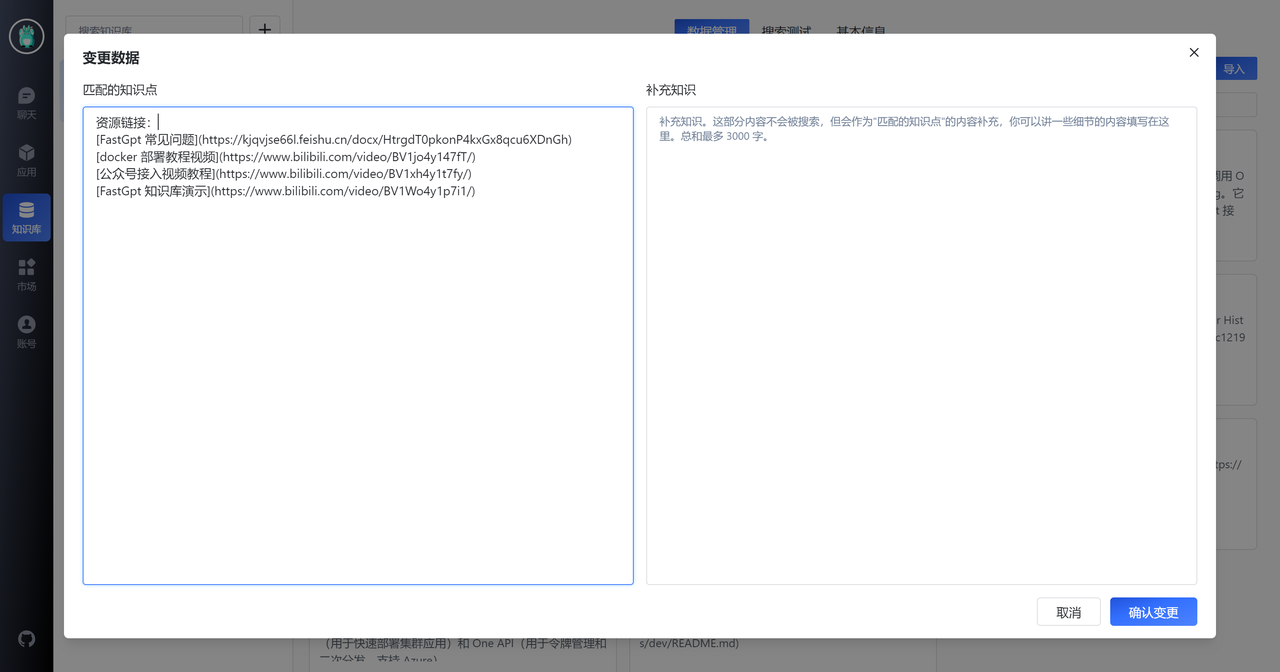
此外,我们观察到第一列第三个知识点。这个知识点是介绍了 FastGPT 一些资源链接,但是 QA 拆分将答案放置在了 A 中,但通常来说用户的提问并不会直接问“有哪些链接”,通常会问:“部署教程”,“问题文档”之类的。因此,我们需要将这个知识点进行简单的一个处理,如下图:
我们先来创建一个应用,看看效果如何。 首先需要去创建一个应用,并且在知识库中关联相关的知识库。另外还需要在配置页的提示词中,告诉 GPT:“知识库的范围”。
整体的效果还是不错的,链接和对应的图片都可以顺利的展示。
5.5 录入社区常见问题
接着,我们再把 FastGPT 常见问题的文档导入,由于平时整理不当,我们只能手动的录入对应的问答。
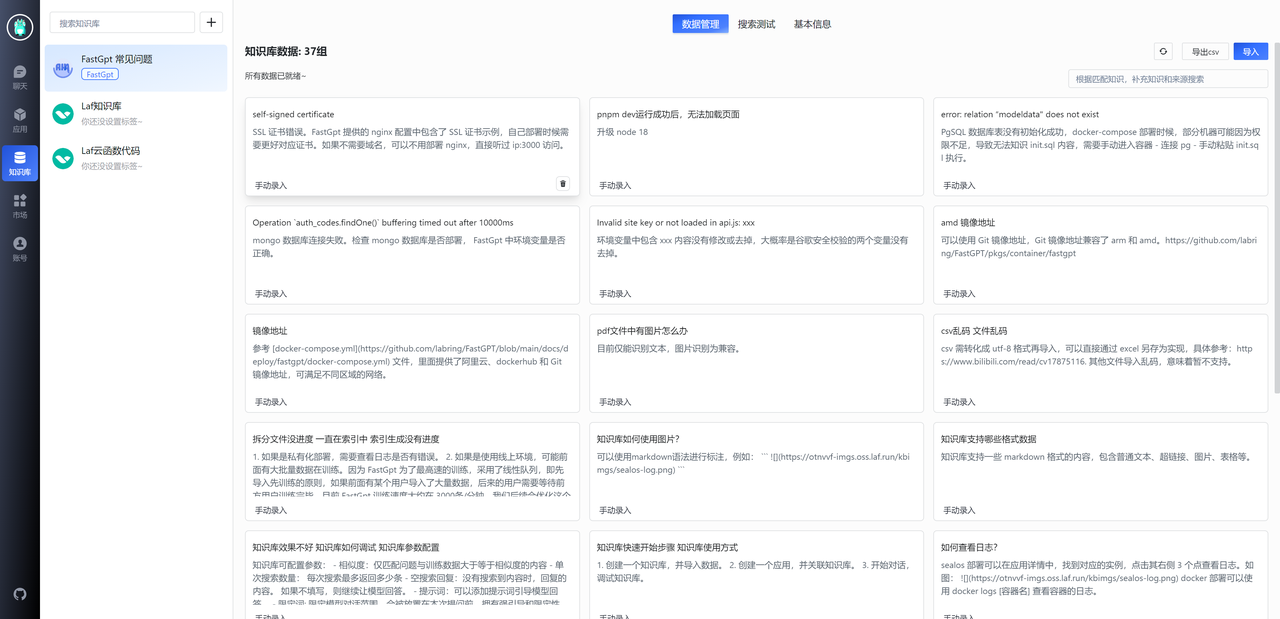
导入结果如上图。可以看到,我们均采用的是问答对的格式,而不是粗略的直接导入。目的就是为了模拟用户问题,进一步的提高向量搜索的匹配效果。可以为同一个问题设置多种问法,效果更佳。 FastGPT 还提供了 openapi 功能,你可以在本地对特殊格式的文件进行处理后,再上传到 FastGPT,具体可以参考:FastGPT Api Docs
5.6 知识库微调和参数调整
FastGPT 提供了搜索测试和对话测试两种途径对知识库进行微调,我们先来使用搜索测试对知识库进行调整。我们建议你提前收集一些用户问题进行测试,根据预期效果进行跳转。可以先进行搜索测试调整,判断知识点是否合理。
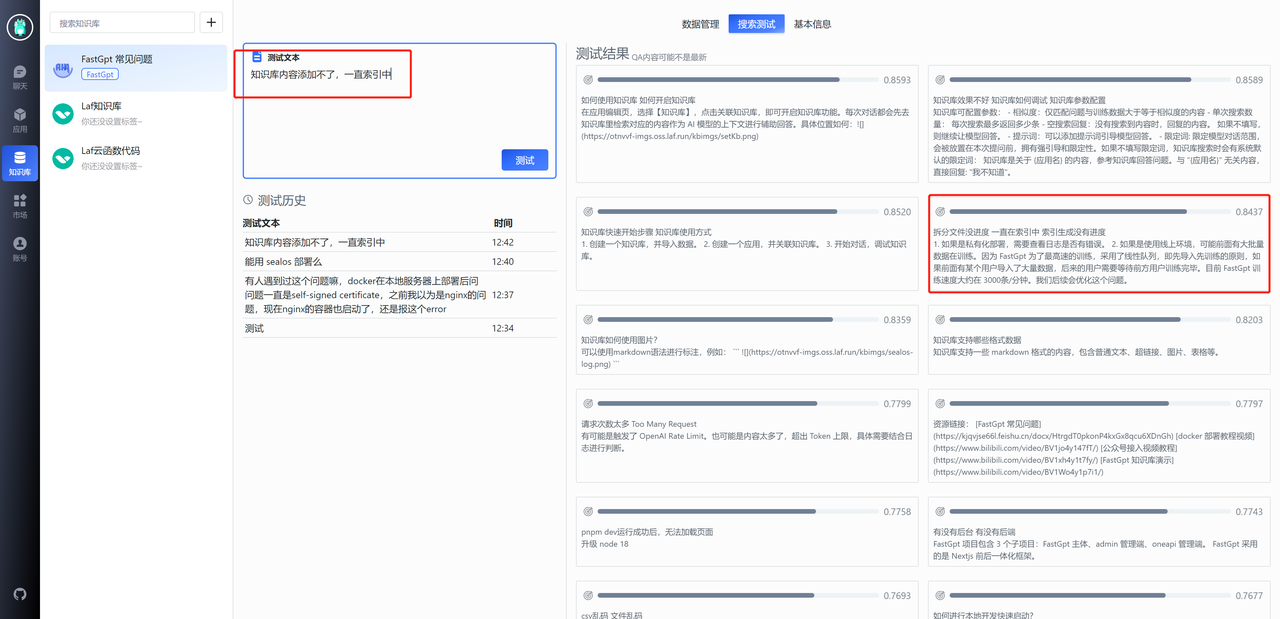
搜索测试
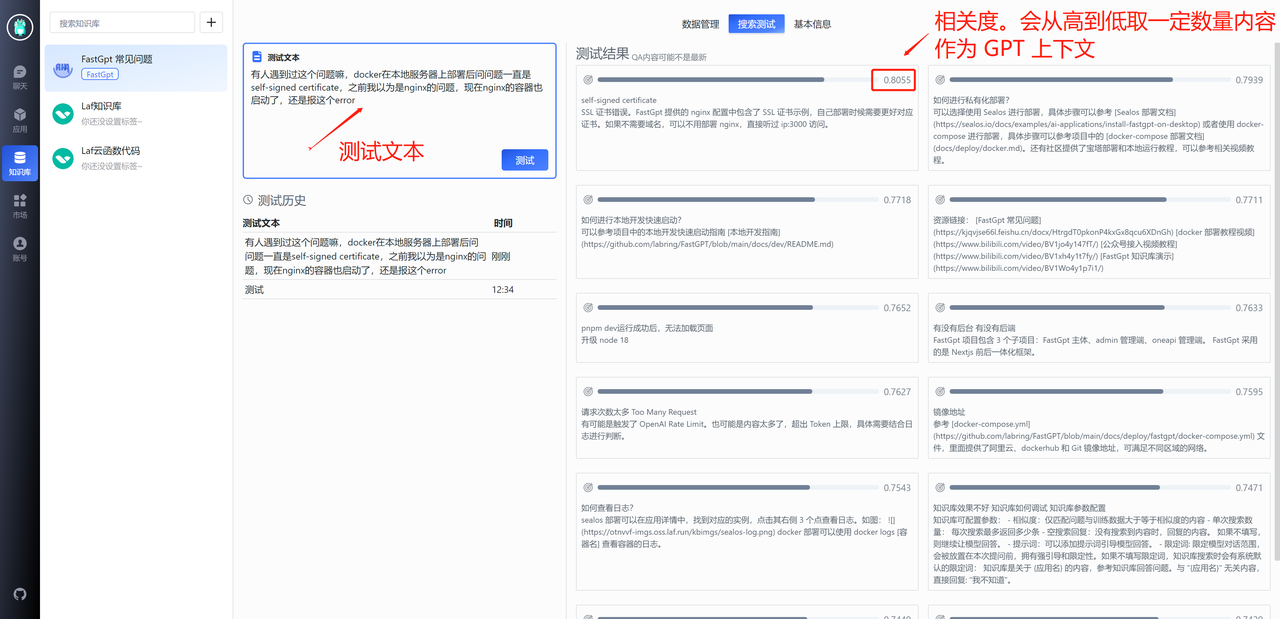
你可能会遇到下面这种情况,由于“知识库”这个关键词导致一些无关内容的相似度也被搜索进去,此时就需要给第四条记录也增加一个“知识库”关键词,从而去提高它的相似度。
提示词设置
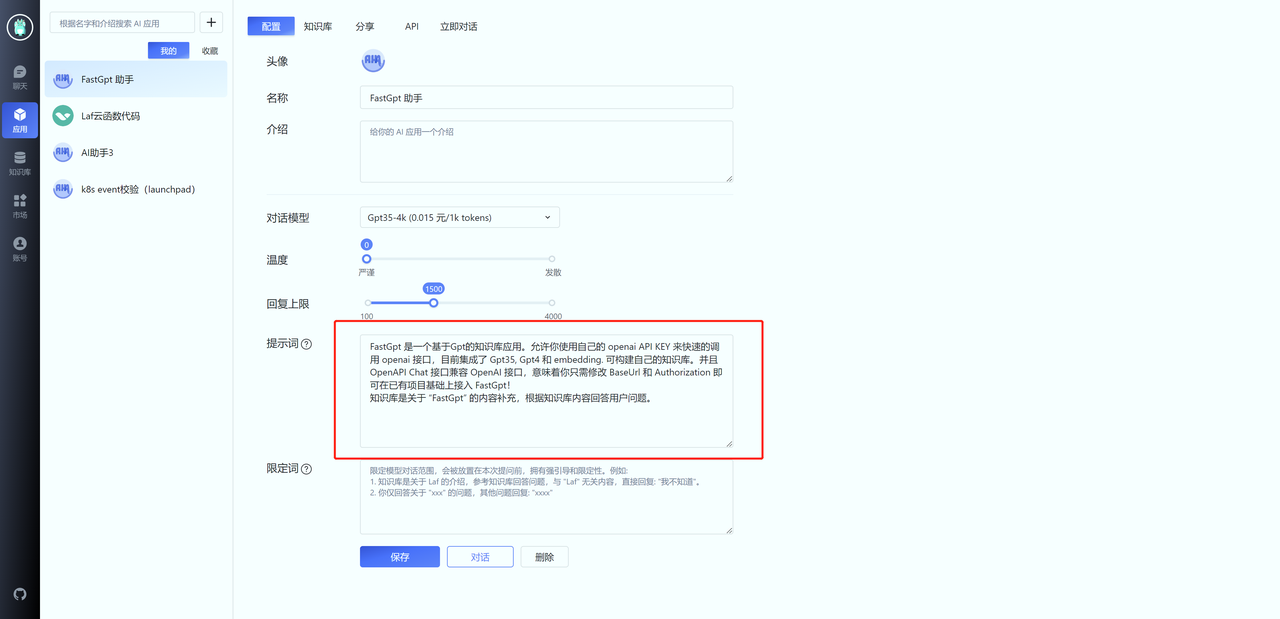
提示词的作用是引导模型对话的方向。在设置提示词时,遵守 2 个原则:
- 告诉 Gpt 回答什么方面内容。
- 给知识库一个基本描述,从而让 Gpt 更好的判断用户的问题是否属于知识库范围。
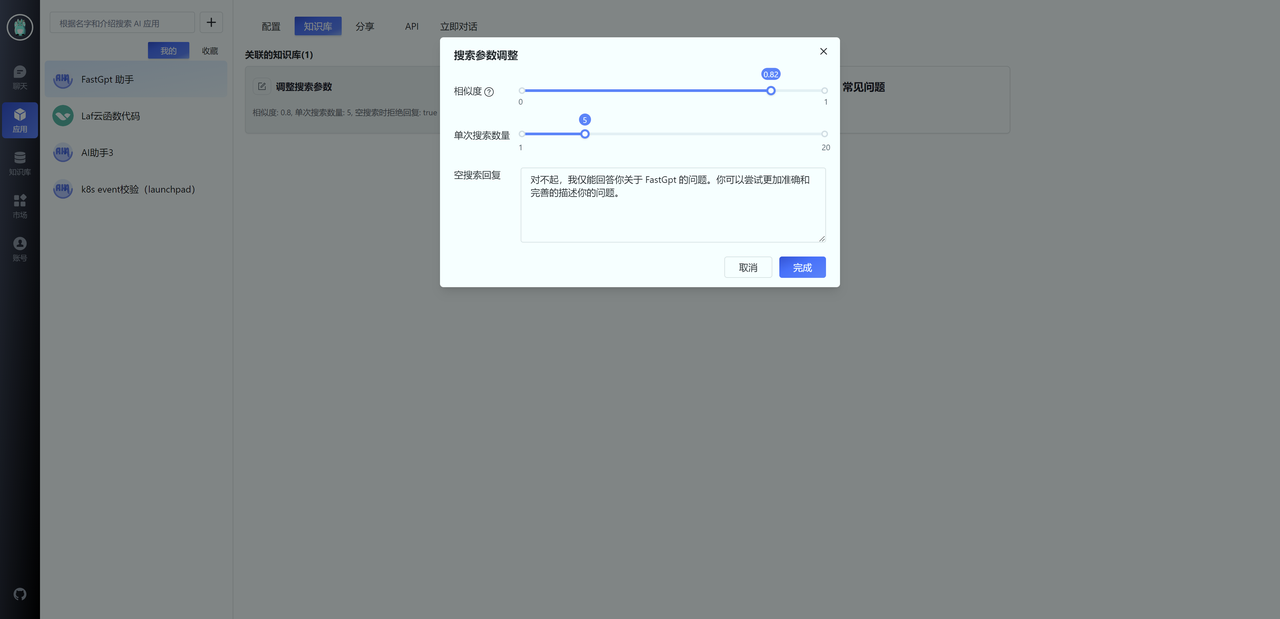
更好的限定模型聊天范围
首先,你可以通过调整知识库搜索时的相似度和最大搜索数量,实现从知识库层面限制聊天范围。通常我们可以设置相似度为 0.82,并设置空搜索回复内容。这意味着,如果用户的问题无法在知识库中匹配时,会直接回复预设的内容。
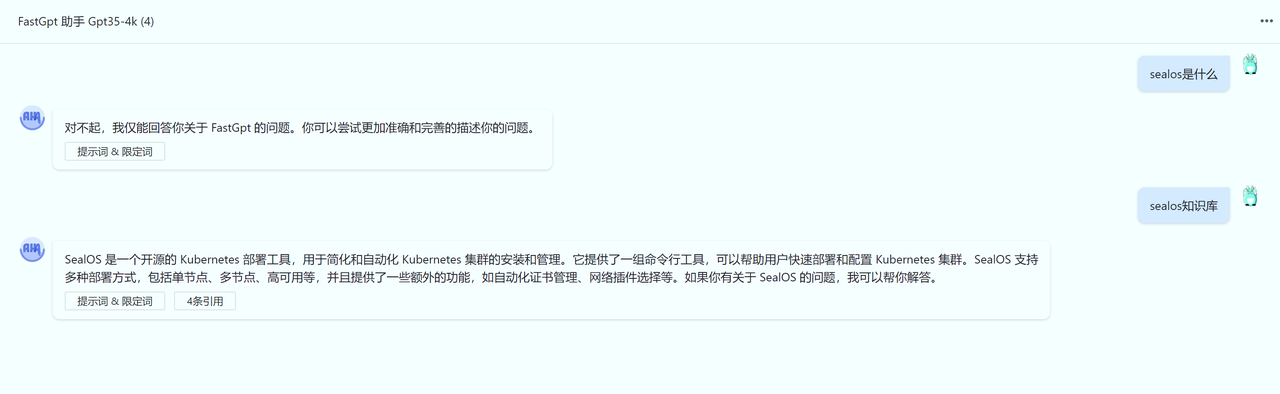
由于 openai 向量模型并不是针对中文,所以当问题中有一些知识库内容的关键词时,相似度 会较高,此时无法从知识库层面进行限定。需要通过限定词进行调整,例如:
我的问题如果不是关于 FastGPT 的,请直接回复:“我不确定”。你仅需要回答知识库中的内容,不在其中的内容,不需要回答。
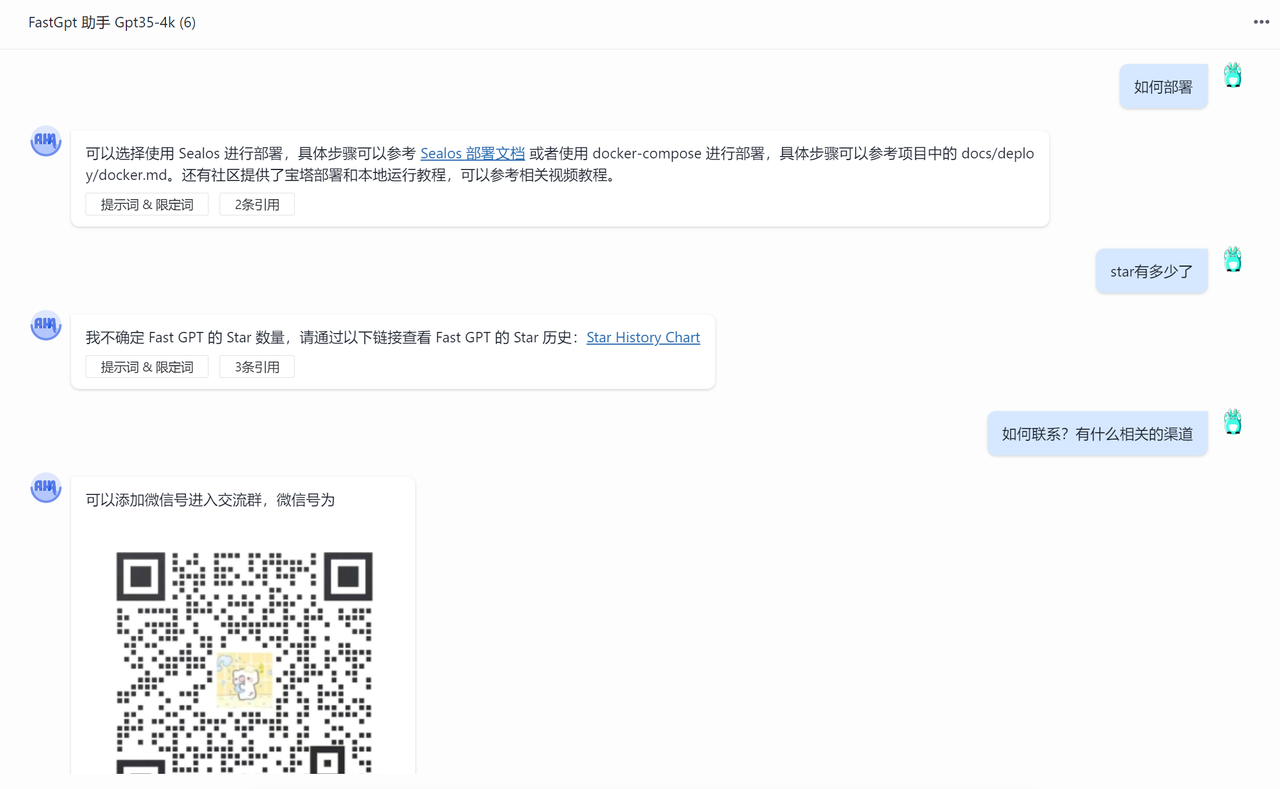
效果如下:

当然,gpt35 在一定情况下依然是不可控的。
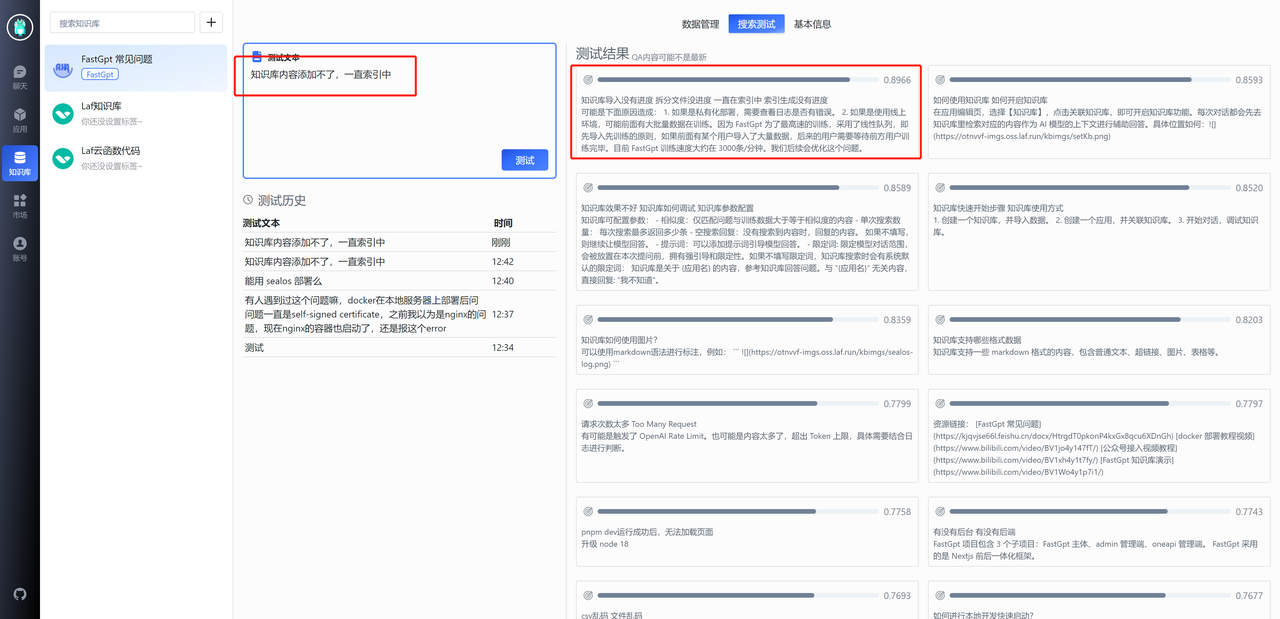
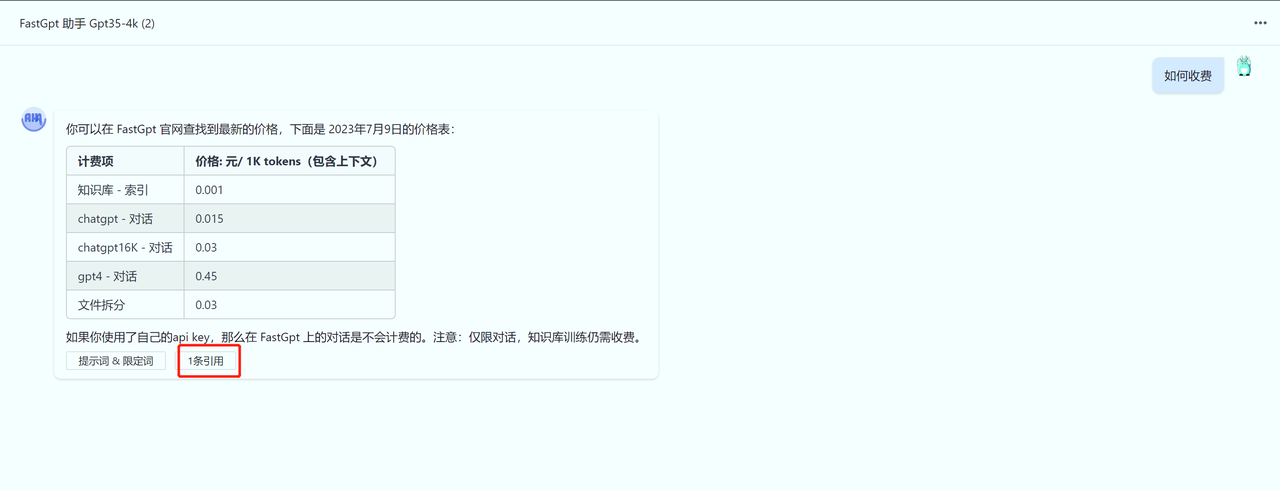
通过对话调整知识库
与搜索测试类似,你可以直接在对话页里,点击“引用”,来随时修改知识库内容。
总结
- 向量搜索是一种可以比较文本相似度的技术。
- 大模型具有总结和推理能力,可以从给定的文本中回答问题。
- 最有效的知识库构建方式是 QA 和手动构建。
- Q 的长度不宜过长。
- 需要调整提示词,来引导模型回答知识库内容。
- 可以通过调整搜索相似度、最大搜索数量和限定词来控制模型回复的范围。